视图是一个抽象的概念,简单的说就是把表中的部分我们关注的内容保存一份出来到视图中,这样我们每次就不需要通过那么多字段的表去查询数据,只需要通过已经过滤出来的我们关系的数据中(视图中)取我们需要的数据。进一步说就是从一张大的表数据中抽离出来一部分我们关注的数据,这部分数据就是可以存放在视图中。向视图提供数据内容的语句为 SELECT 语句, 可以将视图理解为存储起来的 SELECT 语句。
oracle 中的视图
视图的优点
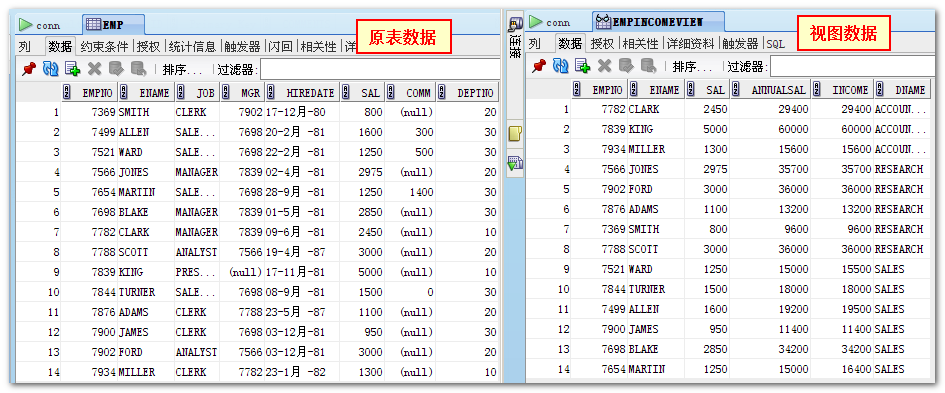
1、简单复杂化的查询 常规情况下我们如果需要在表中查询一部分我们需要的数据,可能要在 where 后面输入很多条件才能过滤出来,而如果把某部分数据单独拎出来做成视图,这样我们就可以直接在缩小了范围的视图中查询需要的数据了,这样就可以简化我们的查询语句,更快的找到需要的数据。 2、限制数据的访问 不难想象,通过上面的图我们就可以看出,原表的很多字段数据都被我们过滤了,在视图中只显示了我们关心的数据。假设有部分重要的且又不需要用户知道的数据,完全可以通过视图隐藏起来。 3、提供数据的相互独立 视图可以使应用程序和数据库表在一定程度上独立。如果没有视图,应用一定是建立在表上的。有了视图之后,程序可以建立在视图之上,从而程序与数据库表被视图分割开来。 4、同样的数据可以有不同的显示方式 我们可以将一些原来表中需要运算的数据在构建视图的同时也直接储存在视图中,不用我们每次再去写运算条件取需要的数据,像上图总的视图数据一样,ANNUALSAL 和 INCOME 字段就是我们自己基于月薪和奖金构建出来的。而基础条件只有月薪和奖金,却在视图中有不同的展现形式。
视图的特性
1、视图是不能提高性能的 在文章开头我们说过,你可以理解为视图就是包装起来的 select 语句,你对视图进行查询只不过就是在 select 中嵌套 select,所以视图并不会提高性能。 2、不建议通过视图修改数据 视图隔离出来的部分数据可能字段名会有差异,且视图中对执行一些 DML 语句有很多限制,所以一般情况下视图都被构建为只读的(后面会讲构建方法)。
创建一个表视图
CREATE OR REPLACE VIEW empvu10 /*or replace 代表如果表存在则修改视图*/
(employee_number, employee_name, job_title) /*创建后视图的字段*/
AS
SELECTemployee_id, last_name, job_id /*数据来源于一个查询*/
FROM employees
WHERE department_id = 10
WITH READ ONLY; /*视图只读*/
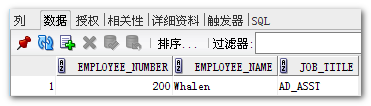
创建后的效果图: